Daily 24 - Apr 22
Class Performance
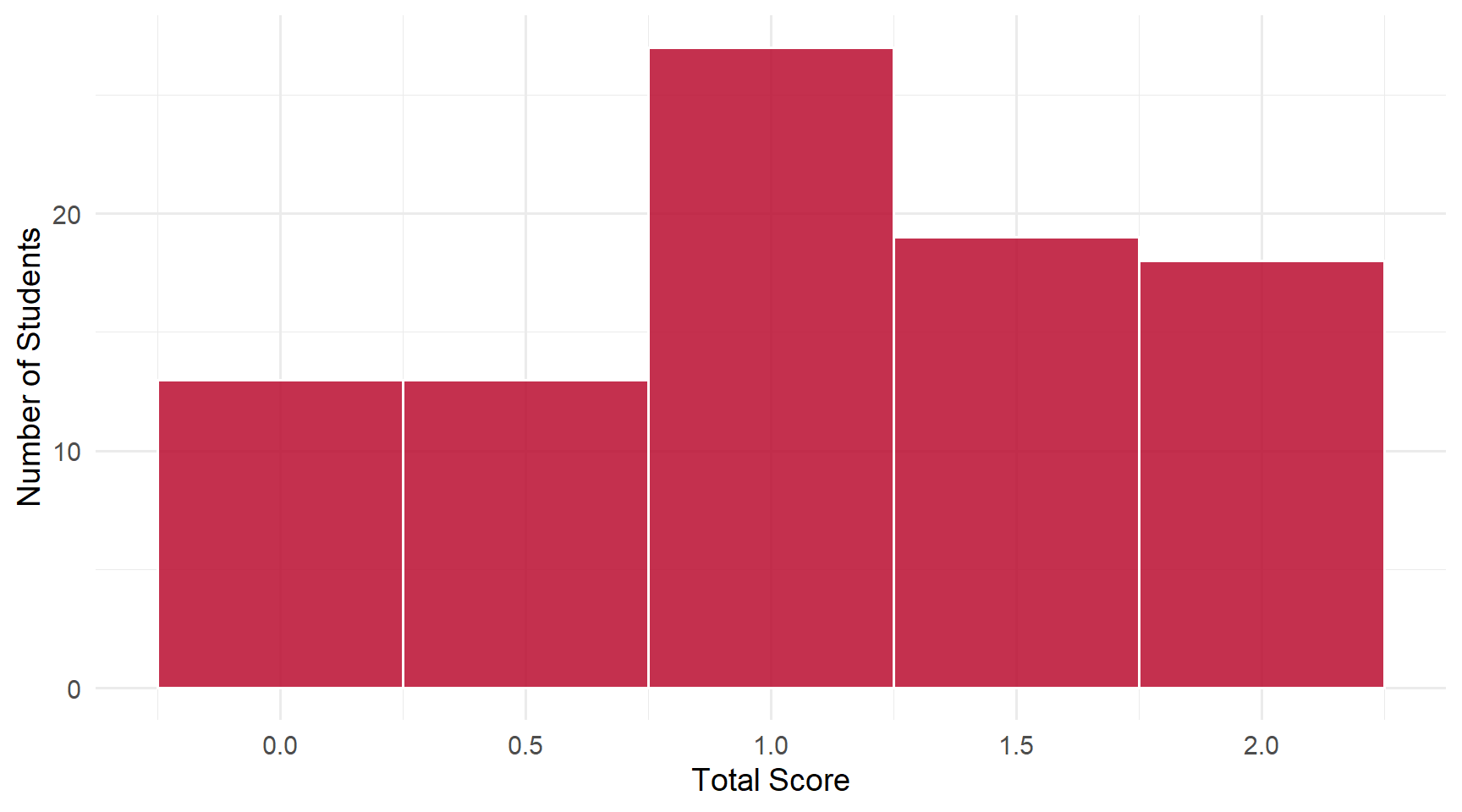
Students: 90 | Mean: 1.09 | Median: 1 | SD: 0.66
This daily had 2 questions. Scores ranged from 0 to 2 out of 2 points.
Score Distribution
Performance by Question
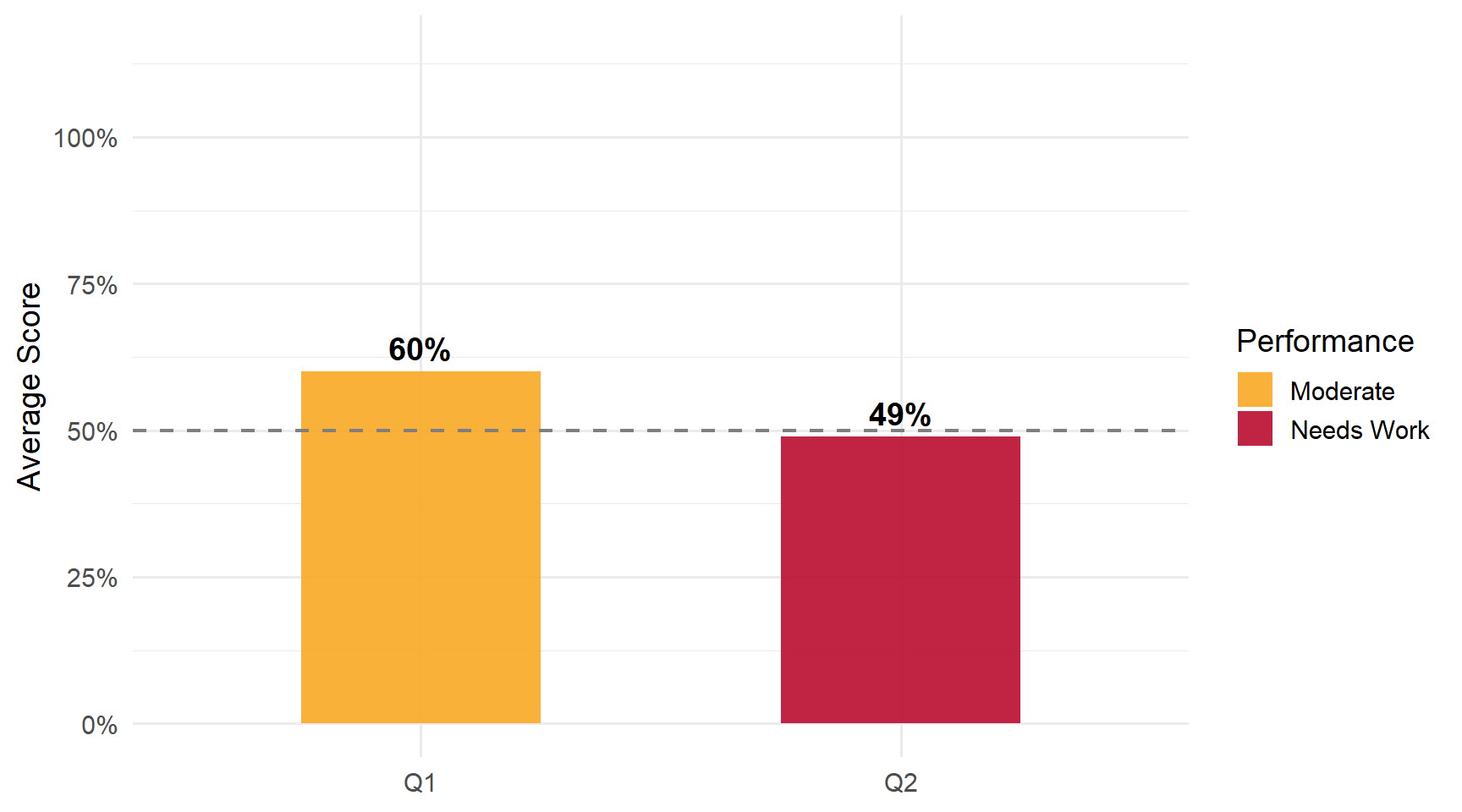
Questions
Q1: Regression Model for E(y_i | x_{i1}, x_{i2})
Correct Answer
\(y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + u_i\)
Common Errors
- Missing the error term (\(u_i\)) — Half credit. The conditional expectation is deterministic; the regression model adds an error.
- Writing \(E(y|x)\) on the LHS — Half credit. The regression model is for \(y_i\) (not its conditional mean) plus an error.
- Missing the intercept (\(\beta_0\)) — Major structural error.
Q2: Regression Model for lm(value ~ sqft + lotsize, data)
Correct Answer
\(value_i = \beta_0 + \beta_1 sqft_i + \beta_2 lotsize_i + u_i\)
Common Errors
- Generic \(x\) notation — Half credit if structure is right but you wrote \(\beta_1 x_{i1}\) instead of the named variables.
- Missing the error term — Half credit. Same issue as Q1.
- Including “data” as a predictor — Zero credit.
datais the data frame argument tolm(), not a covariate.
Key Takeaways
Strengths: Many students recognized the intercept-plus-slopes structure | About 20% earned a perfect 2/2.
Review:
- Always include the error term (\(u_i\)) — A regression model is data-generating: outcome = systematic part + error
- Conditional expectation vs regression — \(E(y|x)\) is the systematic part; the model is \(y_i = E(y_i|x_i) + u_i\)
- Match R formula → math —
lm(y ~ x1 + x2)writes out as \(y_i = \beta_0 + \beta_1 x_{1i} + \beta_2 x_{2i} + u_i\) with the named variables